Apache SkyWalking是一個開源的應用程序性能監控系統,特別為微服務、云原生和容器化架構設計。其啟動加載過程與數據處理存儲服務是整個系統的核心。本文將深入解析SkyWalking的啟動流程,以及其數據處理與存儲服務的工作原理。
一、SkyWalking啟動加載過程
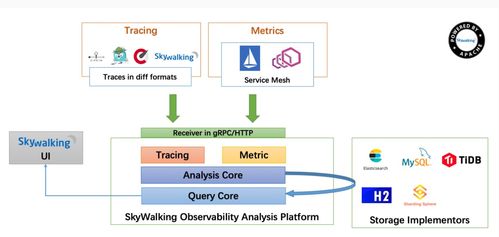
SkyWalking的整體架構分為OAP(Observability Analysis Platform)服務器、存儲后端和探針(Agent)三部分。啟動過程主要指OAP服務器的初始化。
1. 模塊化架構初始化:
SkyWalking采用高度模塊化的設計。啟動時,核心容器(ModuleManager)會根據application.yml配置文件,加載并初始化所有啟用的模塊。每個模塊(如core、cluster、storage、receiver-*等)都通過SPI(Service Provider Interface)機制定義自己的提供者(Provider)。容器會解析模塊間的依賴關系,按正確順序進行初始化。
- 核心服務啟動:
- 集群管理服務:如果配置了集群模式(如Zookeeper、Kubernetes、Consul等),相應的集群管理模塊會啟動,用于OAP節點間的服務發現與協調。
- GRPC/HTTP服務器啟動:接收來自各類探針(如Java、.NET、Node.js等Agent)上報的遙測數據(Trace、Metric、Log)的Receiver模塊會啟動其GRPC和/或HTTP服務器,監聽特定端口。
- 查詢服務啟動:提供GraphQL查詢接口的模塊啟動,為UI前端提供數據查詢能力。
3. 存儲模塊初始化:
這是啟動的關鍵環節。Storage模塊的Provider(如elasticsearch、mysql、tidb、influxdb等)被加載。它會執行以下操作:
- 根據配置連接指定的存儲后端。
- 檢查并創建必要的索引/表結構(如果配置了自動創建)。
- 初始化各種DAO(Data Access Object)對象,這些DAO封裝了所有指標、追蹤、服務等數據的增刪改查邏輯。
4. 流式處理拓撲構建:
SkyWalking的核心數據處理引擎是一個輕量級的流式處理系統。在啟動時:
- Receiver模塊將接收到的原始數據發布到不同的“流”(Stream)中。
- 聚合器(Aggregator) 模塊會為每一種指標(如Service、Endpoint、Service Relation的指標)創建并啟動一個處理“窗口”。這些窗口定義了數據的聚合周期(如分鐘、小時、天等)。
- 系統構建出一個完整的數據處理流水線,原始數據經過解析、格式化、聚合后,最終由存儲模塊的DAO持久化到數據庫中。
5. 就緒與服務注冊:
所有核心服務初始化完畢后,OAP服務器標記自身為就緒狀態。在集群模式下,會向集群管理器注冊自身實例,開始正常處理工作負載。
二、數據處理與存儲服務詳解
數據處理與存儲是SkyWalking將原始遙測數據轉化為可觀測性洞察的核心。
- 數據處理流程(流式處理模型):
- 數據接收:Agent通過GRPC將Trace、JVM Metrics、Service/Instance屬性等數據推送到OAP的相應Receiver。
- 數據解析與流轉:Receiver對數據進行初步解碼和校驗,然后將其發送到內部的消息隊列(實際上是基于Disruptor或其它隊列的流)。每個數據流(如Trace流、Meter流)都有明確的定義。
- 實時聚合:這是最關鍵的一步。聚合器(Aggregator)訂閱這些流。例如:
- Trace數據:會被用于生成拓撲圖(Service Relation)、計算端點(Endpoint)的響應時間和成功率。一條Trace會被拆解成多個服務間(Service Relation)的調用指標。
- Metric數據:如JVM數據,會按照服務(Service)、服務實例(Instance)的維度進行分鐘級的聚合,計算CPU使用率、堆內存使用率等的平均值、最大值等。
- 窗口化處理:聚合以時間窗口(通常為1分鐘)為單位進行。系統會為每個聚合指標(如Service的每分鐘響應時間)維護一個窗口。窗口關閉時(每分鐘的第59秒),窗口內的數據會完成最終聚合,并觸發持久化。分鐘級的數據會進一步向上聚合到小時級和天級窗口。
- 派生指標生成:系統會根據原始指標計算派生指標,如Apdex(應用性能指數)、百分位數(P50, P90, P99)等。
2. 存儲服務與設計:
SkyWalking的存儲設計是面向度量和拓撲分析的,并非原始日志的存儲。
- 存儲模型:
- 指標存儲:以時間序列數據為核心。例如,
service<em>traffic表存儲服務元數據,service</em>resp_time表存儲服務響應時間的分鐘/小時/天指標。存儲時包含時間桶(Time Bucket)、實體ID(如服務ID)、值等字段。
- 拓撲存儲:服務間調用關系(Service Relation)和端點間調用關系(Endpoint Relation)也被建模為特殊的指標進行存儲,包含來源ID、目標ID和調用指標(如流量、延遲、成功率)。
- 軌跡存儲:Trace數據通常被采樣存儲。詳細軌跡(Segment)存儲在一個獨立的索引/表中,通過Trace ID進行查詢。為了平衡性能和成本,SkyWalking支持慢查詢追蹤、僅存儲錯誤Trace等策略。
- 多存儲后端支持:通過Storage Provider抽象層,支持多種存儲:
- Elasticsearch:最常用的選擇,利用其強大的搜索和聚合能力,適合存儲Trace和明細數據。
- 關系型數據庫(MySQL, PostgreSQL, TiDB等):通過分表(按時間、按類型)存儲聚合后的指標數據,適合中等數據量級和成本敏感的場景。
- 其他時序數據庫:如InfluxDB等。
- 數據TTL(生存時間):存儲模塊支持為不同類型的數據(如詳細Trace、指標數據)配置不同的保留策略,自動清理過期數據以控制存儲成本。
###
SkyWalking的啟動是一個按依賴順序初始化模塊化服務的過程,最終構建出一個完整的流式數據處理管道。其數據處理核心在于“實時接收、窗口化聚合、多級下鉆”,將海量的原始遙測數據高效地轉化為面向服務的指標、拓撲和軌跡信息。存儲層則通過靈活的Provider機制適配不同后端,以優化的數據模型持久化這些分析結果,為上層UI提供快速查詢和分析的基礎。這種設計使得SkyWalking在微服務監控場景下,既能保證處理性能,又能提供豐富的可觀測性能力。